

Сравнение текстовых ИИ-моделей GPT:
какую выбрать маркетологу в 2026 году

Содержание:
___Выбор правильной ИИ-модели для маркетинга - это уже не роскошь, а необходимость. Рынок генеративных моделей преобразился за последние два года. Если еще недавно выбор был ограничен, сегодня маркетологи и специалисты по поисковому маркетингу стоят перед серьезным вызовом: какую модель выбрать для своих задач?
___Генеративные ИИ прошли путь от экспериментальных систем к надежным инструментам, которые решают реальные бизнес-задачи. Но вот парадокс: чем больше вариантов, тем сложнее решение. Вы тратите часы на тестирование, сравнение и анализ, вместо того чтобы сосредоточиться на том, что действительно важно - результатах вашей кампании.
___Генеративные ИИ прошли путь от экспериментальных систем к надежным инструментам, которые решают реальные бизнес-задачи. Но вот парадокс: чем больше вариантов, тем сложнее решение. Вы тратите часы на тестирование, сравнение и анализ, вместо того чтобы сосредоточиться на том, что действительно важно - результатах вашей кампании.
Генеративные модели открыли три ключевые точки роста для маркетинговых команд. Первая - автоматизация создания контента. Вторая - оптимизация процессов аналитики и сбора семантики. Третья - персонализация коммуникаций на масштабе. Эти точки роста не просто экономят время. Они освобождают ваши команды от рутины и позволяют сосредоточиться на стратегии. Поэтому мы провели масштабное, объективное тестирование: восемь ведущих моделей, пять этапов, единые критерии оценки, слепое голосование. Результаты, которые помогут вам принять правильное решение прямо сейчас - без потери времени и ресурсов.

Методология тестирования
Для честного сравнения восьми моделей мы использовали один и тот же промт для каждой. Это критично. Если вы будете давать разные инструкции разным моделям, результаты будут несравнимы. Как если бы вы просили одного копирайтера писать рекламу, а другого - техническое описание.
Унифицированный промт - это строго определенная инструкция, которая содержит все необходимые параметры: целевую аудиторию, формат вывода, требования к стилю, ограничения. Ничего субъективного. Модели получают одинаковые условия и работают в одинаковых рамках.
Мы разработали промты для каждого этапа: генерация названий, структура статьи, написание текста, адаптация стиля. Каждый промт был протестирован несколько раз, чтобы убедиться в его ясности.
Слепое голосование - это ключевой момент нашей методологии. Система была оценки прозрачна. Каждый критерий оценивался по шкале от 1 до 10. Perplexity Comet видел только результаты, без подписей и идентификаторов. Это исключает предвзятость системы.

Этап-1: Тестирование названий
Для первого этапа мы выбрали задачу, которая отражает реальные потребности маркетологов. Требовалось создать привлекающее, информативное название для статьи о автоматизации сбора семантического ядра через инструмент AdPump. Название должно работать в поисковых системах, быть кликабельным в соцсетях и передавать основную ценность.
Каждая из восьми моделей сгенерировала три варианта названий. Всего получилось 24 варианта. ИИ выбирала лучший вариант от каждой модели перед тем, как оценивать его по основным критериям. Это позволило каждой модели показать себя в лучшем свете - её вариант, а не первый попавшийся результат.
Результаты первого этапа показали четкую иерархию. На вершине с суммой 46 баллов оказалось название, которое сумело совместить все ключевые элементы: цифры, временной контраст, практическую ценность и эмоциональное воздействие. Этот заголовок звучит как реальная история успеха, а не просто информационное сообщение.

Победивший вариант был выбран как основа для следующего этапа. Это название станет ориентиром для структуры статьи, которую будут генерировать модели на этапе 2
Этап-2: Тестирование структур
На втором этапе все восемь моделей получили задачу: создать детальную структуру статьи на основе победившего заголовка из первого этапа. Структура должна была включать основные разделы (H2), подразделы (H3) и логическую последовательность информации. Требования были четкими: структура должна быть интересна маркетологам, содержать практические советы, быть оптимизирована для поиска и поддерживать нарастающий интерес читателя.
Это была сложнейшая задача. Потому что структура - это каркас статьи. Если каркас плохой, вся статья развалится, неважно насколько хорош текст внутри. Структура определяет логику, иерархию информации и путь читателя через материал.
Восемь моделей сгенерировали восемь разных структур. Количество разделов варьировалось от пяти до восьми. Количество подразделов - от десяти до четырнадцати. Это показывает, что модели интерпретируют задачу по-разному. Одни предпочитают детальное разбиение, другие - более обобщенный подход.
Интересное наблюдение: модели, которые победили на первом этапе (генерация названий), не обязательно победили на втором. Это указывает на то, что разные модели имеют разные сильные стороны. Одна хороша в творчестве, другая - в архитектуре информации.
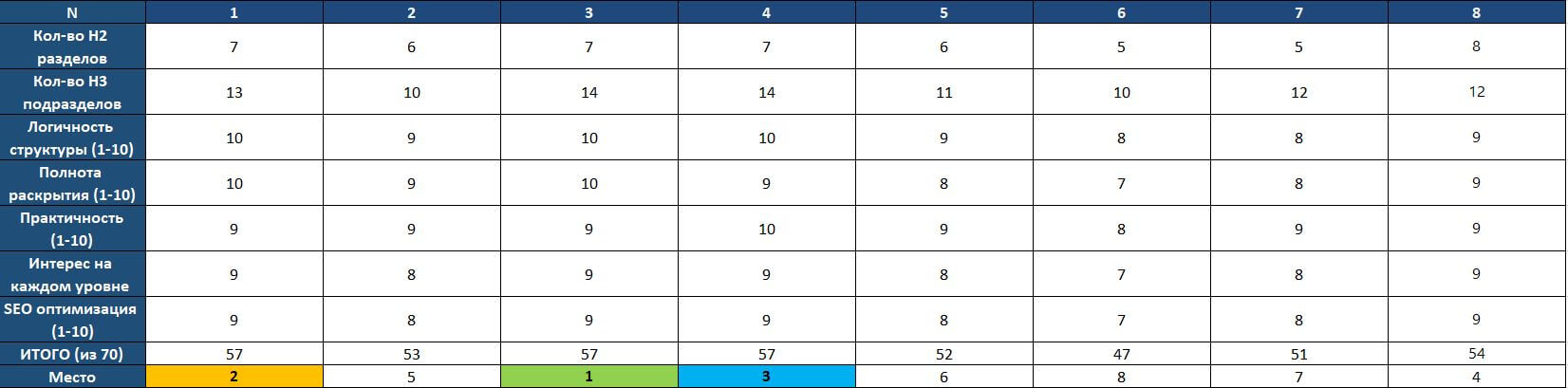
На вершине результатов с 57 баллами оказались модель 3 и модель 1. Обе получили максимальные баллы за логичность, полноту раскрытия и SEO-оптимизацию. Различие было в деталях. Модель 3 набрала 57 баллов и заняла 1-е место, а модель 1 набрала те же 57 баллов, но заняла 2-е место. Это произошло из-за анализа распределения баллов по критериям.
Победившая структура (модель 3) стала основой для третьего этапа - написания полной статьи. Эта структура хорошо сбалансирована: достаточно деталей, но не перегружена. Логична, понятна и интересна. Каждый раздел ведет к следующему, как звенья в цепи.
Этап-3: Написание коротких статей
Все восемь моделей получили одинаковую структуру (победившую на этапе 2) и должны были написать полную статью. Требования были жесткие: статья должна быть информативной, содержать практические примеры, соответствовать стилю для маркетологов, быть оптимизирована для поиска и держать внимание читателя от начала до конца.
Здесь важна одна деталь: объем текста в этом этапе не был ограничен жестко. Модели сами решали, насколько подробно раскрывать каждый раздел. Это открывало окно для сравнения подходов. Одни модели предпочитают лаконичность, другие - детальность.
Восемь моделей сгенерировали восемь статей. Объемы варьировались от 1450 до 3889 слов. Это огромный разброс. Модель 8 написала в два с половиной раза больше текста, чем модель 3. Длина текста - это выбор модели. Некоторые считают, что лучше дать читателю все детали. Другие верят в принцип: лучше меньше, да лучше. Оба подхода имеют логику. Вопрос в том, какой работает эффективнее для маркетолога, который спешит и хочет быстро получить информацию.
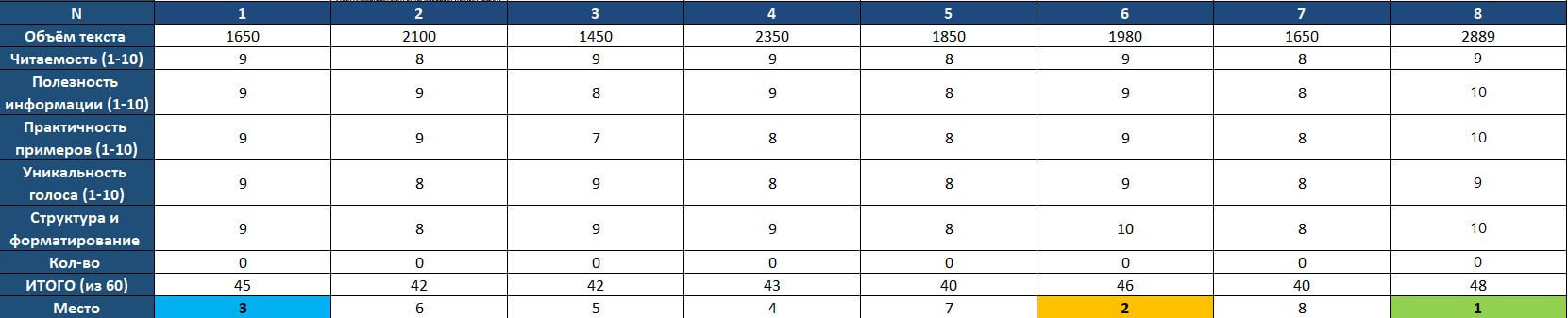
На первом месте - модель 8 с 48 баллами. Она получила максимум за информативность, структурность, соответствие аудитории и стиль. Её статья была достаточно объемной (3889 слов), но не страдала многословностью. Каждое слово работало на смысл.
Победившая статья модель 8 стала основой для следующего этапа - адаптации под требуемый стиль. Эта статья была достаточно информативной, чтобы раскрыть тему глубоко, но при этом показатели читаемости и соответствия аудитории оставались на топовом уровне.
Этап-4: Адаптация статьи под авторский стиль
Это был тест на эмпатию модели. Взять готовую статью-победителя (от модели 8) и переписать её так, чтобы она зазвучала голосом конкретного автора. Не просто изменить слова, а изменить стиль текста.
Задача была сложной: сохранить фактуру и пользу оригинала, но внедрить специфический стиль: профессиональный тон, практическая польза, минимум воды, четкая структура AIDA, фокус на «вы». И самое главное - добавить личный опыт, но без лишнего «яканья». Текст должен звучать как разговор эксперта с коллегой, а не как сухая инструкция или рекламный буклет.
Восемь моделей выдали восемь версий одной и той же статьи. Разница была колоссальной. Некоторые модели восприняли «стиль» слишком буквально, добавив сленг и эмодзи там, где это не нужно. Другие, наоборот, ушли в сухой академизм, потеряв энергию оригинала. Третьи попытались просто сократить текст, выбросив важные детали. Но были и те, кто уловил суть. Они изменили ритм предложений, добавили риторические вопросы, переформулировали пассивный залог в активный. Текст стал живым, динамичным.

Абсолютным лидером стала модель 8 с 46 баллами. Она снова доказала свое превосходство. Эксперты назвали её «исключительно сильным кандидатом». Идеальное попадание в требования по практичности: подробные таблицы, три варианта действий в рекомендациях. Структура четкая, линейная. Максимум баллов за практичность примеров и сохранение информации (по 10 баллов).
Оценивали адаптацию по пяти жестким критериям: соответствие стилю, практичность примеров, сохранение информации, соблюдение структуры AIDA и энергичность текста. В итоге, финальная статья, которая пойдет в публикацию - это версия от модели 8. Она сочетает в себе глубокую экспертизу оригинала с идеальной стилистической огранкой. Это текст, который не нужно править. Его можно брать и публиковать.
Этап-5: Проверка качества текста
После стилистической обработки каждый текст прошел суровую техническую проверку. Все восемь текстов показали 100%уникальности, но уникальность - это только начало. Количество ошибок варьировалось от 5 до 25, объем текстов - от 3000 до 8500 символов, и больший объем не гарантировал лучший результат. Показатель заспамленности держался в нормальном диапазоне 46-52, вода варьировалась от 10% до 15%. ГлавРед дал оценки чистоты 8,3-8,9 и читаемости 9,0-9,6 баллов - почти все модели показали хороший уровень технического мастерства, и ни один текст не вызывал претензий с этой стороны.
Мы проверили каждый текст через пять популярных детекторов ИИ-контента. Результаты варьировались от 0% до 100% в зависимости от инструмента и модели. Одни детекторы оказались слишком мягкими и почти всё пропускали, другие - чрезмерно агрессивными и помечали человеческие тексты как ИИ. Главный вывод: детекторы AI дают несогласованные результаты и не могут служить надежным показателем качества.
Модели с лучшим стилистическим результатом не всегда показывали низкие проценты AI-контента, что подтверждает: качество текста и его «похожесть на ИИ» - это разные параметры. Мы учитывали все показатели: уникальность (максимум за 100%), читаемость и чистоту по ГлавРеду, минимизацию воды, ошибок и спама. Детекторы ИИ мы обрабатывали отдельно: средний результат по всем пяти детекторам, при этом взвешивая надежность каждого.
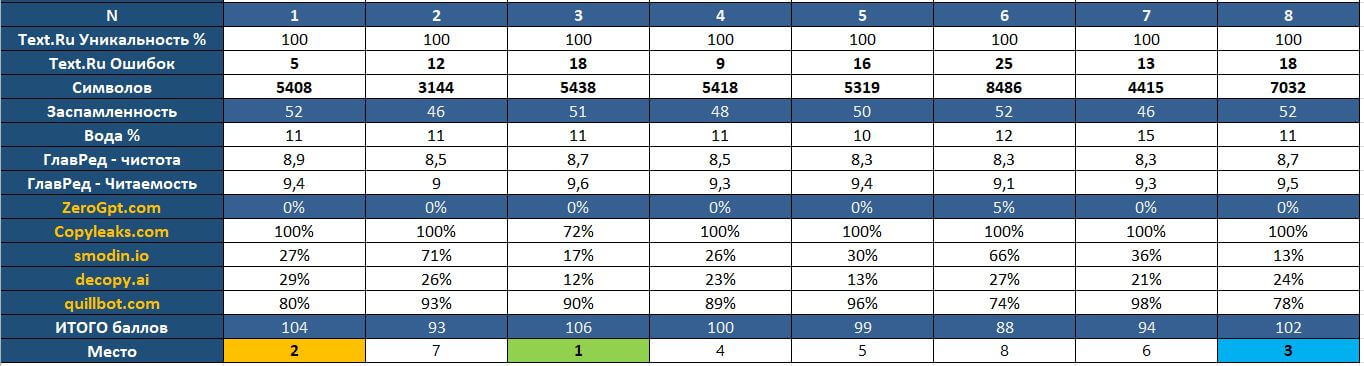
Главный вывод: текст, который выглядит идеально стилистически модель 8, может иметь технические недочеты. Текст, который немного уступает в стиле модель 3, может быть технически чище. Идеальный текст - это компромисс между обоими подходами.
На протяжении всех пяти этапов тестирования за номерами скрывались восемь реальных лидеров рынка.
- Модель 1 - это YandexGPT 5 Pro, российский гигант, который знает русский язык как никто другой.
- Модель 2 - GigaChat MAX, еще один отечественный игрок с амбициозными целями.
- Модель 3 - ChatGPT 4o, флагман OpenAI, который переопределил рынок генеративных моделей.
- Модель 4 - Claude Sonnet 3.5 от Anthropic, модель, заслужившая репутацию за аккуратность и безопасность.
- Модель 5 - DeepSeek R1, китайская модель, которая недавно взорвала рынок своей производительностью.
- Модель 6 - Gemini 2.5 Pro от Google, универсальный солдат с мультимодальными возможностями.
- Модель 7 - Perplexity AI, поисковый ИИ, который переосмысляет информационный поиск.
- Модель 8 - Perplexity AI Pro, премиум-версия того же сервиса с расширенными возможностями.

Заключение
Тестирование раскрыло несколько важных истин. Во-первых, не существует универсального чемпиона. Модели, которые побеждают в творчестве, не обязательно лидируют в архитектуре информации. Во-вторых, качество и стиль - это разные параметры. Текст может выглядеть идеально, но содержать технические недочеты. В-третьих, русский язык остается сильной стороной российских моделей: YandexGPT и GigaChat показали лучшие результаты. В-четвертых, доступность в России имеет значение -модели, работающие нативно, экономят время на интеграцию. Главный вывод: вам нужна система, которая умеет оценивать оба аспекта одновременно и адаптировать инструменты под вашу задачу.
Профессиональные маркетинговые команды работают не с одной моделью, а с целой экосистемой. На этапе генерации идей используют одну. На этапе структурирования - другую. На финальной адаптации - третью. Каждая модель делает то, что она делает лучше всего. Результат? Текст, который превосходит то, что можно получить от одной модели. Скорость, которая удваивается. Качество, которое выходит на новый уровень. Но здесь возникает новая проблема: как управлять всеми этими моделями одновременно? Как отслеживать качество на каждом этапе? Как автоматизировать этот процесс?
«Bdv-Direct.ru» - Это не просто агентство - это партнер, который умеет интегрировать лучшие ИИ-модели в единую систему маркетинга, автоматизируя выбор оптимальной модели для каждой задачи, отслеживая качество и гарантируя соответствие вашему стилю. Пора переходить от вопроса «какую модель выбрать?» к вопросу «как масштабировать мой маркетинг с правильными инструментами?» и готов помочь вам сделать это уже сегодня.